BODC Argo Data Management
Data generation activities:
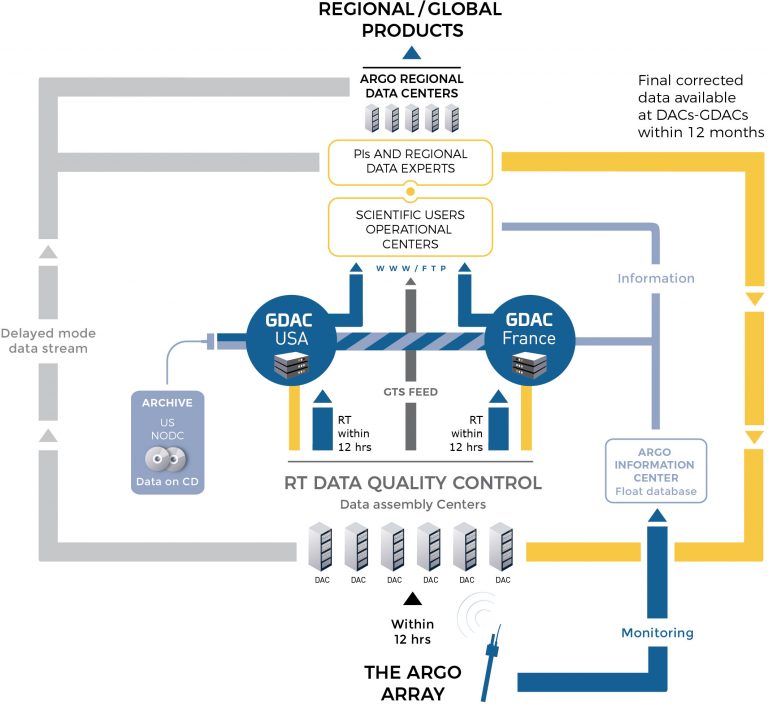
Raw Argo data are automatically captured by the BODC RT Argo processing system. The data are also run through the automated RTQC tests to flag any spikes and suspicious outliners or earlier detected drifts. BODC DAC delivers core and BGC data in netCDF format to the UK Met Office four times a day, where it is subsequently issued to the GTS in BUFR format. The incoming files and RT workflow are monitored each working day to ensure the systems are running correctly. After the generation, archiving and distribution of RT Argo data to GDAC within about 24 h, data will be undertaken for further real-time adjustment and delayed mode quality control (DMQC) processing.
Performing Real-time adjustments:
BODC Argo DAC reviews the Argo data based on any relevant QC recommendations from external partners (Ifremer, Coriolis, and international QC groups). Then, the RT core and BGC data are run through the visual inspection to immediately identify and flag any unexpected data behaviour, spikes, and outliners. Some Core, Deep and BGC Argo data require additional analysis after a few months from deployment to remove any potential bias on data due to instrument errors or other failures. This requires the use of statistical tools and scientific expertise for comparing the Argo float data with other independent datasets like climatology.
Performing Delayed-mode quality control:
The DMQC analysis of both BGC and Core Argo data are be performed 1 year after float deployment. This process needs to be repeated every year (since the new data arrives) up to the end of the float life. Similar to RT adjustments, DMQC of Argo parameters includes an initial visual inspection. Another step is a review of Argo data based on well-established methods and software using other independent datasets to detect any developed over time suspicious or inaccurate measurements. Any inconsistencies or incorrect data are appropriately adjusted (if possible), while any wrong data are flagged in the dataset to ensure the highest quality of science-ready data.